This midterm review is organized around one central question:
How do AI systems represent knowledge, reason with it, and still make useful decisions when the world is uncertain, vague, noisy, or too complex for hand-written rules?
The course moves from symbolic knowledge and rule-based reasoning to statistical and learning-based systems. The important part is not only remembering definitions, but understanding what each method represents, how it performs inference, when it works well, and where it fails.

1. Knowledge Representation
Knowledge Representation, or KR, is the foundation of the course. Its purpose is to turn raw information into a structure that an AI system can store, query, update, and reason over.
A good representation should balance five requirements:
- Expressiveness: can it represent the knowledge needed by the domain?
- Computational efficiency: can inference be done at a practical cost?
- Scalability: does it still work as the knowledge base grows?
- Interpretability: can humans understand why the system made a decision?
- Modifiability: can the system be updated when the world changes?
The main KR methods include symbolic logic, semantic networks, frames, rule-based systems, expert systems, and knowledge graphs. Structured knowledge, such as tables, ontologies, and RDF triples, is easier to query and reason over. Unstructured knowledge, such as text and images, usually needs NLP, deep learning, or retrieval-augmented generation before it can support reliable reasoning.

2. Symbolic Logic
Symbolic logic gives AI systems a formal language for representing claims and checking whether conclusions follow from premises.
In propositional logic, the basic unit is an atomic proposition with a truth value. Common connectives include negation, conjunction, disjunction, implication, and biconditional. The highest-yield rule is implication:
$$ P \to Q $$This implication is false only when \(P\) is true and \(Q\) is false. It does not allow us to infer \(P\) from \(Q\). That mistake is the fallacy of affirming the consequent.
Core valid inference rules:
- Modus Ponens: from \(P\) and \(P \to Q\), infer \(Q\).
- Modus Tollens: from \(\neg Q\) and \(P \to Q\), infer \(\neg P\).
- Hypothetical Syllogism: from \(P \to Q\) and \(Q \to R\), infer \(P \to R\).

First-Order Logic extends propositional logic with objects, predicates, functions, variables, and quantifiers. It is more expressive because it can describe relationships among objects rather than only isolated true-or-false statements.
Important exam traps:
- Do not reverse implications.
- Check whether variables are free or bound.
- Quantify only what the question states.
- Distinguish terms, formulas, and sentences.
- Remember that predicates return truth values, while functions return objects.

3. Wumpus World
Wumpus World is a compact example of logical reasoning from observations. The agent receives local percepts, such as breeze or stench, and uses rules to infer which squares may contain pits, the Wumpus, or safe moves.
The key idea is:
$$ \text{World knowledge} + \text{observations} \Rightarrow \text{inferred safety or danger} $$For example, a breeze at a square means at least one neighboring square has a pit. It does not identify exactly which one. No breeze is stronger evidence: it means none of the neighboring squares has a pit.
This distinction is a common exam target. "At least one", "none", and "exactly one" are logically different claims.

4. MYCIN and Expert Systems
MYCIN is an early rule-based expert system for bacterial infection diagnosis and treatment support. It is important because it shows the structure of a classical symbolic AI system:
- a knowledge base containing long-term rules and facts
- a working memory containing case-specific data
- an inference engine that applies rules
- a rule acquisition system for editing expert knowledge
- an explanation system that answers WHY and HOW questions
MYCIN used production rules of the form:
|
|
It also used confidence factors to handle uncertain evidence:
$$ CF(\text{conclusion}) = CF(\text{premise}) \times CF(\text{rule}) $$For AND premises:
$$ CF(A \land B \land C) = \min(CF(A), CF(B), CF(C)) $$The WHY/HOW distinction matters:
- WHY explains why the system is asking a question.
- HOW explains how the system reached a conclusion.
MYCIN mattered because it separated knowledge from inference and made explanations part of the system. Its limits were also clear: knowledge acquisition was expensive, rules were hard to maintain, medical knowledge changed quickly, and deployment raised legal and ethical concerns.

5. Decision Trees
Decision trees are interpretable, non-parametric supervised learning models. They recursively split data using feature tests until each leaf can make a prediction.
For classification trees, a leaf usually predicts the majority class. For regression trees, a leaf predicts the mean target value. Each root-to-leaf path can be rewritten as an IF-THEN rule, which connects decision trees back to symbolic rule-based systems.
The learning process is usually greedy:
- Choose the best feature or threshold to split on.
- Split the data into subsets.
- Repeat recursively on each subset.
- Stop when the data is pure, no features remain, or a stopping rule is met.
The key exam point is that accuracy alone is not a good split criterion. A split may not improve immediate accuracy but may reduce uncertainty and make later splits better. That is why impurity measures are used.
Entropy:
$$ H(X) = -\sum_x p(x)\log_2 p(x) $$Information gain:
$$ IG(Y|X) = H(Y) - H(Y|X) $$Gini impurity:
$$ Gini(D) = 1 - \sum_i p_i^2 $$ID3 uses information gain, C4.5 extends ID3 to continuous features and uses gain ratio, and CART uses binary trees with Gini for classification or squared error for regression.

6. Ensembles: Bagging, Random Forests, and Boosting
Ensemble learning combines multiple predictors. The motivation is simple: many imperfect models can be more reliable than one unstable model.
Bagging trains models independently on bootstrap samples and aggregates predictions by voting or averaging. It mainly reduces variance. Random forests extend bagging by choosing only a random subset of features at each split, which decorrelates trees and improves averaging.
Boosting is sequential. Each new learner focuses more on the mistakes of previous learners. This often reduces bias and improves the final model step by step.
AdaBoost trains weak learners, reweights misclassified samples, and combines learners with weighted votes. Gradient boosting fits residuals or gradients of the loss function. XGBoost is an efficient, regularized implementation of gradient-boosted trees with shrinkage, column sampling, and scalable training.
High-yield comparison:
| Method | Training Style | Main Effect |
|---|---|---|
| Bagging | Independent models on bootstrap samples | Reduces variance |
| Random forest | Bagging plus random feature subsets | Reduces correlation and variance |
| AdaBoost | Sequential reweighting of errors | Reduces bias and focuses on hard cases |
| Gradient boosting / XGBoost | Sequential fitting of residuals or gradients | Optimizes loss with regularization |

7. Soft Computing
Soft computing is a family of methods that tolerate uncertainty, partial truth, inaccuracy, and approximation. The goal is not weak computation. The goal is robust decision-making in messy real-world settings.
Hard computing asks for exact truth. Soft computing asks for useful, stable, interpretable decisions when exact truth is unavailable or too brittle.
The most important distinction is:
- Uncertainty: we do not know which state of the world is true.
- Vagueness: the concept itself has blurry boundaries.
Probability asks: How likely is it?
Fuzzy logic asks: To what degree is it true?

8. Fuzzy Logic and Bayesian Reasoning
Fuzzy logic maps truth values to the interval \([0,1]\). A membership function measures how strongly an object belongs to a fuzzy set:
$$ \mu_A(x) \in [0,1] $$For example, \(\mu_{\text{Tall}}(183cm) = 0.6\) does not mean a 60 percent chance of being tall. It means degree 0.6 membership in the concept Tall.
Common fuzzy operators:
$$ \neg A = 1 - A $$$$ A \land B = \min(A, B) $$$$ A \lor B = \max(A, B) $$Bayesian reasoning updates belief after observing evidence:
$$ P(H|e) = \frac{P(e|H)P(H)}{P(e)} $$Naive Bayes is a probabilistic classifier that assumes features are conditionally independent given the class:
$$ P(x|C=c) \approx \prod_i P(x_i|C=c) $$The assumption is often not perfectly true, but the method is simple, fast, scalable, and frequently strong as a baseline.


9. Logic Neural Networks
Logic Neural Networks, or LNNs, combine neural learning with logical reasoning. Neural networks are strong at pattern recognition but weak at consistency and explainability. Symbolic logic is interpretable and precise but brittle under noise and hard to scale manually. LNNs try to blend these strengths.
The main idea is to convert logical formulas into syntax-tree neural structures. Each logical neuron corresponds to a sub-formula or logical operator. Instead of assigning only one truth value, LNNs often reason with truth bounds:
$$ 0 \le L \le U \le 1 $$The workflow is:
- Initialize bounds for atomic facts.
- Propagate upward through logical operators.
- Propagate downward from parent formulas to child constraints.
- Iterate until convergence.
- Inspect target bounds and classify the result.
Common classifications:
| Bound Condition | Interpretation |
|---|---|
| \(L \ge \alpha\) | Definitely true |
| \(U < \alpha\) | Definitely false |
| \(L < \alpha < U\) | Uncertain |
| \(L > U\) | Contradiction |
The most important exam warning is to classify bounds first, then reason. Do not treat fuzzy truth or LNN bounds as ordinary probability.



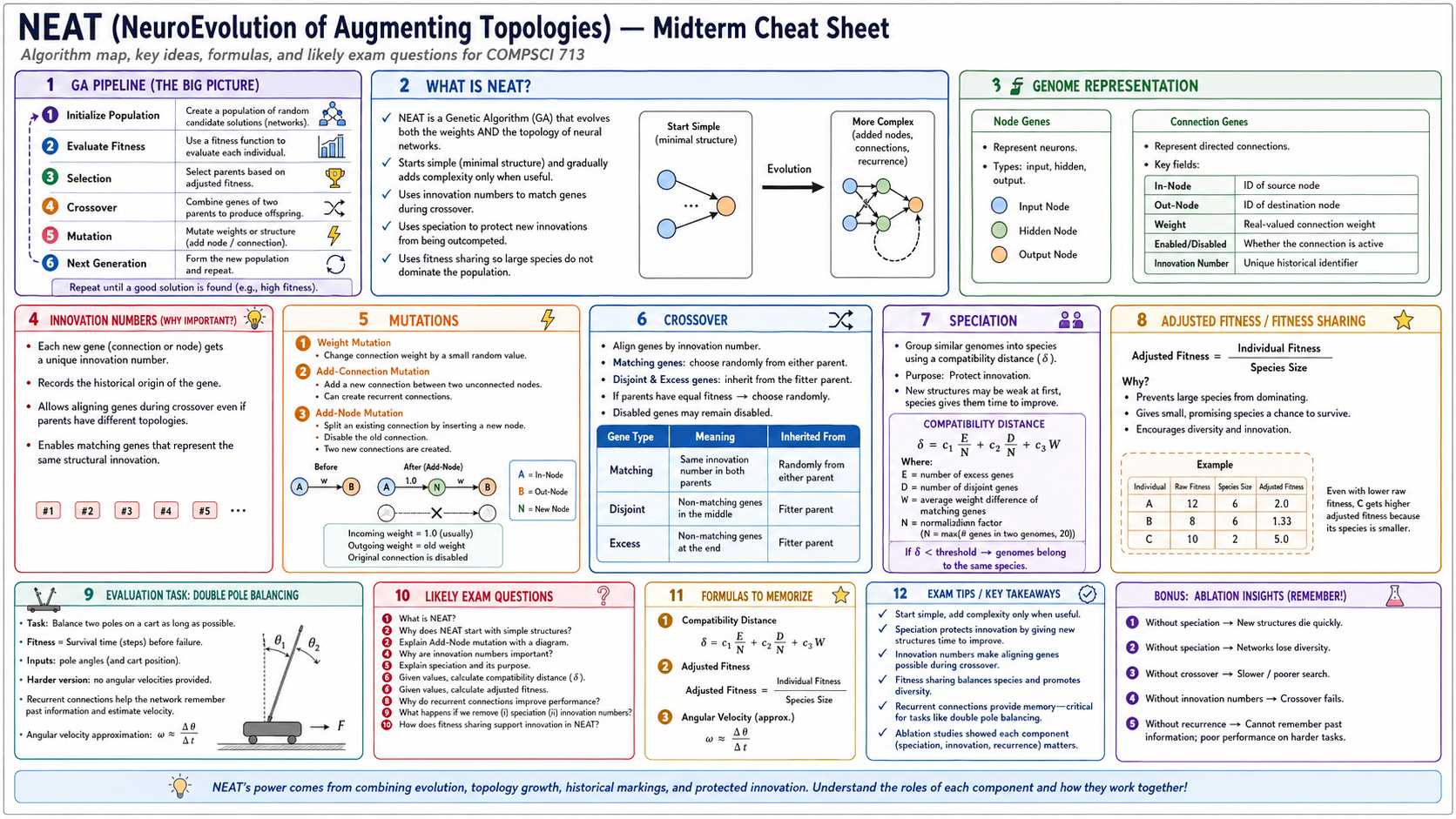
10. NEAT
NEAT stands for NeuroEvolution of Augmenting Topologies. It is a genetic algorithm that evolves both neural network weights and neural network topology.
NEAT starts simple and adds complexity only when useful. This is a major design idea: instead of beginning with a large network, the algorithm begins with a minimal structure and gradually evolves nodes, connections, and recurrent links.
Key mechanisms:
- Weight mutation changes connection weights.
- Add-connection mutation adds a new connection.
- Add-node mutation splits an existing connection by inserting a new node.
- Innovation numbers record the historical origin of genes.
- Crossover aligns genes by innovation number.
- Speciation protects new structures from being eliminated too early.
- Fitness sharing prevents large species from dominating the population.
The compatibility distance is commonly written as:
$$ \delta = c_1 \frac{E}{N} + c_2 \frac{D}{N} + c_3 W $$where \(E\) is excess genes, \(D\) is disjoint genes, \(W\) is average weight difference of matching genes, and \(N\) normalizes genome size.
The adjusted fitness is:
$$ \text{Adjusted Fitness} = \frac{\text{Individual Fitness}}{\text{Species Size}} $$NEAT's strength comes from combining evolutionary search, topology growth, historical markings, and protected innovation.

11. How to Answer Midterm Questions
Most strong answers follow a simple structure:
- Define the term clearly.
- State the mechanism or formula.
- Apply it to the given scenario.
- Interpret the result in plain English.
- Mention one strength, limitation, or assumption if relevant.
For compare-and-contrast questions, compare along stable dimensions: representation, inference method, strengths, weaknesses, and use cases.
For calculation questions, write the formula first, substitute values carefully, compute step by step, and finish with a sentence explaining what the number means.
For scenario questions, do not dump formulas. Name the method, explain why it fits the setting, state one caveat, and connect the answer back to the problem.

12. Final Memory Map
The midterm topics connect naturally:
- KR explains how knowledge is represented.
- Logic explains how conclusions follow from rules.
- MYCIN shows rule-based reasoning in a practical expert system.
- Decision trees learn rule-like structures from data.
- Ensembles improve unstable learners by combining many models.
- Soft computing handles uncertainty, vagueness, and approximation.
- LNNs combine neural learning with logical consistency.
- NEAT evolves both neural weights and neural structures.
The safest exam mindset is: define precisely, reason step by step, interpret formulas in words, and always mention the assumptions behind the method.
